
Introduction
Welcome to our comprehensive post on the Kubernetes Architecture Overview. In this extensive course, we'll go deep into Kubernetes' internal operations and give you a thorough grasp of its design. Pods, controllers, nodes, and services, along with other essential elements and ideas that make up the Kubernetes ecosystem, will be examined. You'll have a strong understanding of Kubernetes architecture by the end of this article, enabling you to take full advantage of its capabilities for coordinating and managing containerized workloads. This article is your key to releasing the full potential of this formidable orchestration platform, regardless of your level of experience with Kubernetes or your desire to learn more about it.
The robust orchestration platform Kubernetes, commonly referred to as K8s, is used to automatically manage and configure containerized applications at scale. K8s has become the go-to tool for orchestrating containers with the development of containers as an essential part of delivering modern applications.
We hope to provide you a thorough grasp of the Kubernetes platform in this post. We shall investigate its architecture and look at its features. It is advised to have prior knowledge of containerization, microservices, immutable design, and infrastructure-as-code ideas in order to fully understand the material covered here.
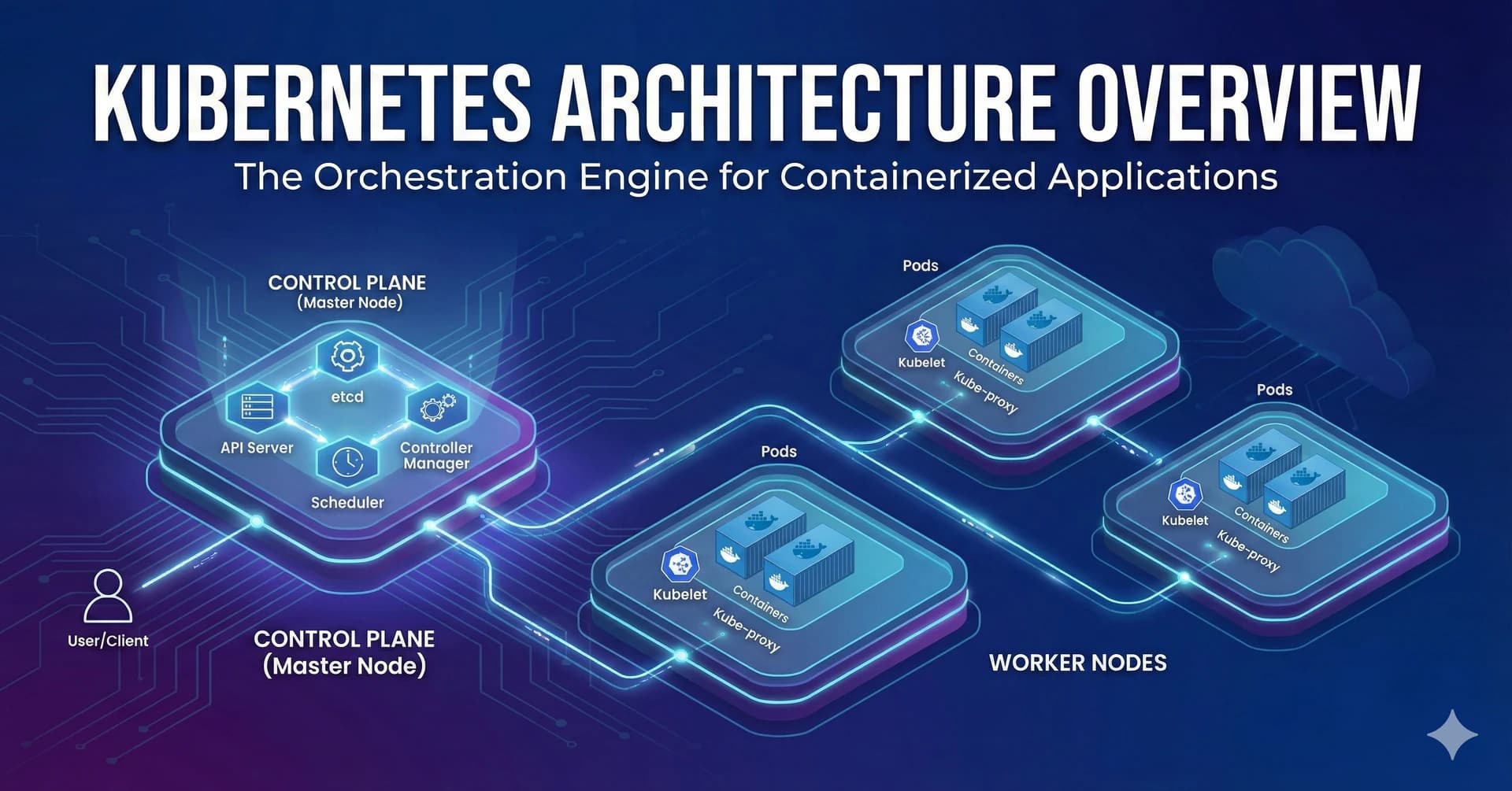
Kubernetes Architecture
The various parts that make up the K8s architecture are shown in the diagram below. Following is a description of each essential element.
Containers: A container is a self-contained software instance that has all the necessary libraries and software packages to operate a standalone "micro-application." If you're unfamiliar with containers, see our article outlining their function.
A key component of the K8s design are pods, which are collections of one or more containers. For instance, K8s may clone a pod to scale out, add more CPU and memory as necessary, or even replace a downed pod automatically. IP addresses are assigned to pods. A "controller" oversees a scalable "workload" made up of a collection of pods. These workloads are connected to "services" that stand in for all of the pods. Despite the scaling or destruction of some pods, a service load balances web traffic among the pods. It's important to note that storage volumes are also affixed to pods and made accessible to pod-containing containers.
An API server is used to create, update, and delete the resources that a controller maintains. A controller is a control loop that evaluates the discrepancy between the desired state and the actual state of the K8s cluster. The collection of pods that the controller controls is determined by the label selectors that make up the controller. There are several different kinds of controllers in K8s, including the Replication Controller (which replicates pods for scaling), the DeamonSet Controller (which ensures that each node receives a single copy of a designated pod), the Job Controller (which schedules software to run at a specific time), the CronJob Controller (which schedules jobs that run periodically), the StatefulSet Controller (which controls stateful applications), and the Deployment Controller (which controls stateless applications).
A node is a physical or virtual server that can be used to schedule pods. Every node has a kubelet pod, a kube-proxy pod, and a container runtime (more on these three things to come). Both manual and automated scaling is possible for node groups (also known as autoscaling groups or node pool groups).
K8s storage volumes offer persistent data storage that is accessible for the duration of the pod. A storage volume may be shared by containers inside a pod. A storage volume can also be accessed directly by a node.
Services: A Kubernetes service is a group of connected pods. This is an illustration of a K8s service.
In Kubernetes Architecture Services, a "label selector" specified in a service configuration file is of utmost importance. By allocating them an IP address and a DNS name, it enables the grouping of pods that make up a single service. In order to effectively decouple the frontend from the backend, the service then equally distributes incoming traffic among the pods that meet the label selector.
On each node, the kube-proxy component manages network services and directs traffic between worker nodes. It ensures effective network operations by maintaining network rules and allowing communication between services and pods.
Every node has a Kubelet component, which connects Kubernetes with the containers through communication. It enables efficient management and monitoring by transmitting data to Kubernetes about the status and well-being of containers.
The program in charge of running containers is known as the container runtime. Popular container runtimes include CRI-O, Docker, and containerd. The Kubernetes environment can deploy and operate containerized apps thanks to these runtimes.
The Controller Plane, controlled by the Kubernetes master, sits at the center of the Kubernetes architecture. It manages workloads and acts as the cluster's central control unit, acting as a communication interface. The Scheduler, Controller Manager, etcd, and API Server are just a few of the parts that make up the Controller Plane.
Etcd serves as a storage mechanism for the cluster's configuration information. The API Server uses it to monitor and make the necessary adjustments to bring the cluster's state within the Kubernetes master nodes into line with the desired state.
The interface for internal and external communication with Kubernetes is the API Server. Instructing the pertinent service or controller to update the status object in etcd after processing and validating requests. Users can also alter how workloads are distributed within the cluster.
Based on considerations including CPU and memory needs, policies, label affinities, and data locality, the Scheduler assesses the available nodes and chooses the best location for unscheduled pods.
All Kubernetes controllers are integrated into a single process called the Controller Manager. The controllers are effectively managed as a single process in a DaemonSet, simplifying the overall architecture and cutting down on complexity, even if they theoretically operate as distinct processes.
Kubernetes Functionality
Kubernetes' capabilities go beyond those of an orchestration technology when they are described. It includes six main categories, each of which offers unique capabilities. Here, we go into greater detail about each feature:
Service discovery and load balancing: During times of high traffic, Kubernetes gives each set of pods a distinct DNS name and IP address, ensuring effective load distribution across services that may include several pods.
Automated Rollouts and Rollbacks: Kubernetes enables the seamless rollout of new pods and the replacement of existing ones with them. modifications to configuration can be made without disturbing end users, and an automated rollback capability enables undoing of modifications in the event that deployments are unsuccessful.
Secret and Configuration Management: Without the requirement for image rebuilding, Kubernetes offers secure storage and updating of configuration and secrets. Stack configuration minimizes the chance of data compromise by keeping secrets hidden.
Storage orchestration: To enable seamless integration and administration of storage resources, Kubernetes supports mounting a variety of storage systems, including local storage, network storage, and public cloud providers.
Automatic Bin Packing: Kubernetes effectively distributes containers depending on stated CPU and RAM requirements by utilizing clever algorithms. This functionality enables businesses to improve operational efficiency and optimize resource use.
Self-Healing: Kubernetes automatically restarts containers when they face errors while proactively monitoring the health of pods. Connections to problematic pods are prohibited until the health checks pass successfully, preserving system stability.
Kubernetes helps businesses to move beyond basic orchestration by allowing seamless service discovery, automated rollouts, secure configuration management, flexible storage orchestration, resource optimization, and powerful self-healing capabilities.
Conclusion
The Kubernetes system is complicated. But it has emerged as the most reliable, scalable, and effective platform for orchestrating highly available container-based applications, supporting decoupled and various stateless and stateful workloads, and offering automated rollouts and rollbacks.